Heading 2
TrueMeter: AI Energy Agent That Optimizes Utility Bills
Ever looked at your utility bill? It’s packed with arcane terms: franchise fee surcharge, conservation incentive, electric public purpose, power charge indifference adjustment, on-peak, off-peak, super-off-peak… It might as well be ancient Sumerian. And those are just the line items. Each utility, each energy provider has its own tariffs, schedules, riders, and incentives. Add in the fact that the data comes in inconsistent, non-tabular formats, and parsing it is a nightmare.
Jul 14, 2026
Index
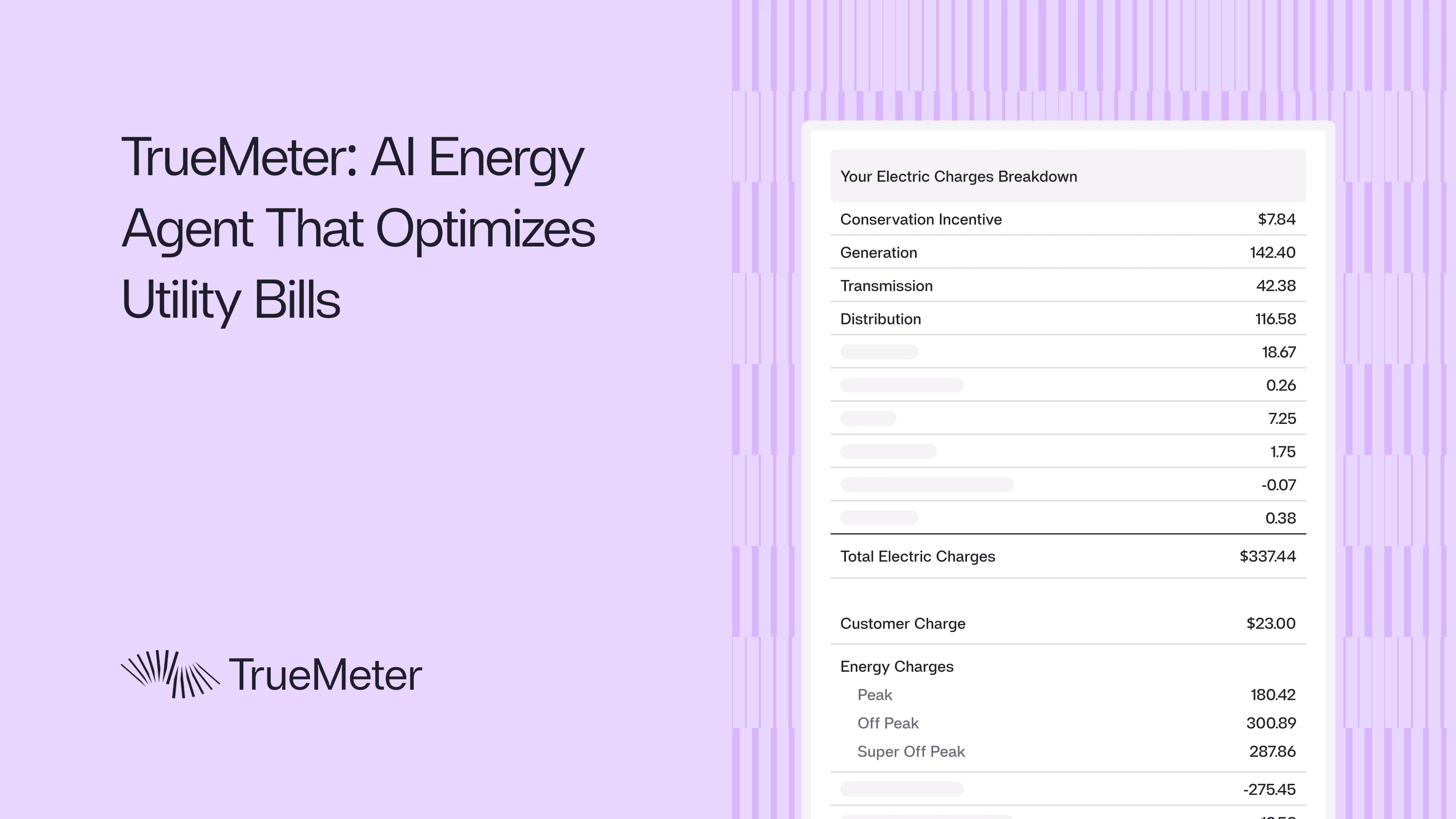
At TrueMeter, we’ve built an AI energy agent that continuously pays, audits and claims savings on energy bills for multi-location businesses. Our platform consolidates bills into a single monthly invoice and provides cross-location actionable insights through LLMs. Our initial engineering challenge was extracting messy data across utilities in different formats and converting it into structured inputs for systems that run customized optimizations, create insights and alerts for each location of the customer. See how we work.
From Chaos to Optimization
To address this challenge, we built an agentic pipeline that tackles the full lifecycle of utility data:
- Automated Data Extraction: Instead of relying on customers to upload files, we can log into utility portals, download utility bills, tariffs and pull smart meter data automatically.
- Parsing Utility Data: AI models process bills, tariff PDFs, and screenshots to identify layouts, detect text, and group relevant entities such as billing dates, charges, and usage data. LLMs enrich this raw extraction by normalizing inconsistent field names, correcting errors, and mapping items into a standardized schema.
- Tariff Normalization: LLMs are especially valuable here. Utility tariffs are often hundreds of pages long, written in legalistic text with complex tables. We use LLM-driven extraction to pull rate components and translate them into JSON with utility-agnostic attributes (e.g., seasonality, time-of-use windows, demand tiers). This makes it possible to compare across thousands of plans.
- Optimization Engine: With clean data in place, our models simulate multiple rate-plan and incentive scenarios. LLMs help generate cost estimation logic for new tariffs quickly, applying utility rules to forecast future bills. By taking last year’s usage as a baseline, adding other considerations and applying switching rules, the optimizer identifies the lowest-cost plan available for the next billing cycles and beyond.
- Automated Billing & Monitoring: Finally, automation workflows execute plan switches and payments, while anomaly detection models flag outlier bills or suspicious line items. The periodic re-optimizations enable us to lock in continuous savings.
Pipeline Overview:
The Problem: Why This Was Previously Impossible
Before LLMs, this kind of large-scale parsing and reasoning across heterogeneous data sources was basically intractable.

Most companies with distributed operations deal with hundreds of utility accounts, each tied to a different electricity or gas provider, each using its own billing format, rate structure, and data schema. Symptoms of this problem show up as unexplained cost increases, inability to benchmark locations, and hours spent manually downloading bills. Optimizing energy spend meant doing all of this by hand:
- Parsing usage data, invoices, and rate plans and normalizing them into spreadsheets
- Running RFPs with alternative energy suppliers and comparing proposals
- Hunting for demand-response programs, incentives, or credit opportunities across dozens of jurisdictions
- Managing contracts, enrollments, and compliance workflows
- Auditing and paying hundreds of utility bills every month, often without a reliable way to verify accuracy
Doing all of this in-house is expensive. Bringing in consultants usually means paying high fees for a one-time audit that's outdated within a quarter. Bill-pay agents don’t fix the root problem either—they process payments, but they don’t explain why costs are rising or how to reduce them. Even though these intermediaries sit on top of all the data, they provide almost no actionable insight.
Traditional vs. Automated Approach:
Common savings opportunities the system identifies include: rate plan mismatches, billing errors and overcharges, and unutilized credits or incentive programs. See example: $60k recovered from a single billing error.
Can we solve this problem with software?
When we started TrueMeter, the question we asked ourselves as developers was whether we could solve this problem in an efficient and automated way from the connection phase to the payment:
Extracting Utility Data at Scale

Pipelines: Our first challenge wasn’t just parsing bills; it was building a fault-tolerant system for acquiring, structuring, and securing data from hundreds of different utility portals across the U.S. Every provider exposes information differently: some have APIs, most don’t, and nearly all hide critical billing details behind customer logins. To make this accessible, TrueMeter built a fully automated ingestion and storage pipeline designed for scale, reliability, and audit-ready transparency:
- Consent & Onboarding: Customers authenticate once via OAuth or credential-based login, and we map their utility meters and accounts through a secure consent record.
- AI-Triage Extraction: an adaptive agent that can log into portals, download PDFs and CSVs, and extract both itemized bill details and granular usage data (15-minute intervals for electricity, hourly or daily for gas). When a portal changes structure, the system automatically retries, regenerates selectors, and submits fix proposals for human review before deployment ensuring self-healing without silent data loss.
- Secure Portal Access: Access to the entire system is managed by enforcing least-privilege secrets and complete audit logs. Every run is idempotent and observable. Concurrency limits, rate-limiting, and backfill re-queues are handled automatically - resulting in a pipeline that can continuously refresh customer data with high reliability and daily freshness from portal availability.
Storage & Observability: Finally, all collected artifacts such as PDFs, interval files, and normalized tables are encrypted and persisted in our database. This includes dashboards for coverage, latency, and data quality, plus alerting on “loud failures” so nothing slips through. The outcome is a unified, utility-agnostic dataset: standardized bills, usage traces, and tariffs ready for analytics, optimization, and reporting.
System Performance Metrics:
In short, we’ve taken a process that once required manual downloads and ad-hoc scraping and turned it into a resilient, AI-assisted ingestion fabric. It scales from dozens to thousands of utilities, handles unpredictable portal changes, and transforms raw, inconsistent energy data into structured clarity: the foundation for every insight TrueMeter delivers.

Parsing the data: how we turn messy bills into trustworthy JSON
To be useful for analytics and optimization, raw bills and downloads must be transformed into a single, auditable dataset. We intentionally keep the parsing design straightforward and platform agnostic: an automated pipeline that accepts raw PDFs, images and interval files, extracts fields and tables, normalizes values, validates schema, and publishes canonical records to cloud storage and a queryable database.
How it works
- End-to-end ingestion: Any bill that lands in the system, whether uploaded by a user, dropped from an automated portal pull, or staged via an admin flow, feeds a single parse entry point. This unifies downstream logic and avoids duplicate or divergent parsing paths.
- Hybrid extraction. The core extraction chain is classical image then OCR then layout analysis then field and table extraction. On top of that we run an AI LLM assisted step that normalizes and interprets ambiguous text, for example mapping a line item that reads “service charge” into a normalized charge type. This AI layer is complementary to deterministic methods: when confidence is low or the field is safety critical such as totals, meter IDs, or usage, we fall back to rule based parsing to avoid hallucination.
- Schema and validation gate. Every parsed document flows through a strict validation gate that enforces types, required fields, and schema versions. Only validated records become canonical. Invalid or low confidence outputs are routed to automated retries, deterministic extraction attempts, or a human review queue. Versioned schemas preserve compatibility as the model and outputs evolve.
- Field level normalization and provenance. Parsed values are normalized for units and formats, reconciled against billed totals, and annotated with provenance and a per field confidence score. Provenance and confidence drive routing into repair workflows or human review so downstream teams can trust and trace values.
- Reconciliation and duplicate handling. At ingest we reconcile parsed usage totals against billed quantities and run multi-key duplicate detection. Discrepancies above configurable tolerances trigger repair workflows rather than silently publishing bad data.
- Operational controls. The pipeline is designed for observability and resilience: parsing metrics such as accuracy and latency, confidence distributions, alerting on loud failures, automatic retries with exponential backoff, and tooling to propose fixes for structural changes in documents. Human reviewers see provenance and per field confidence to triage problems quickly.
- Security and storage. Raw artifacts and parsed outputs are stored encrypted. Every value includes provenance so downstream teams can audit and trace numbers back to source.
The net result is a set of decision ready records: normalized charges, reconciled usage traces, and tariff references with enough provenance and quality controls to power pricing, reporting, and optimization without relying on brittle one-off scrapers or opaque model outputs.
From parsed bills to monthly rate optimization
The optimization problem is simple to state and fiendishly fiddly to implement: given a customer’s predicted usage and a machine-readable description of every rate component, compute what each plan would have charged, then pick a switching strategy that minimizes cost while respecting the utility’s rules.
Inputs
Two engineered artifacts power the whole thing:
- Interval usage: 15-minute electricity intervals (hourly or daily for gas), normalized to meter, timezone and billing windows so clock-aligned TOU logic and demand peaks can be applied correctly. The ingestion pipeline deduplicates, backfills, and preserves per-meter metadata for eligibility checks.
- Tariff/Alternate Rate JSON: an AI-parsed, normalized schema that encodes every billable element: TOU bands, customer charges, demand charges, NBC/PCIA, generation rates and credits, taxes, riders such as business electric vehicle rates and peak-day pricing, and power-factor rules. The schema carries confidence and ambiguity metadata so downstream logic can reject or flag low-confidence fields.
Cost engine: deterministic with LLM help
Cost evaluation is implemented as a deterministic computation that applies tariff rules to the historical usage series with some adjustments to inform the predicted usage:
- Multiply TOU buckets by per-kWh rates, handling voltage and phase splits where applicable.
- Compute demand charges from the highest 15-minute peak in each billing cycle.
- Sum customer charges, non-bypassable charges, taxes, credits and special riders; apply power-factor adjustments and peak-day adjustments where required.
LLMs are used as a pragmatic aid, to generate or normalize plan-specific code and to translate messy tariff language into the structured schema, but the executed cost calculations are deterministic and auditable. The goal is repeatable results that validate against real bills, with target accuracy on the order of 99.5% when compared to actual bills.
Eligibility and switching constraints
Before optimization, an eligibility workflow enumerates the valid rate plans and alternate energy providers for each service account based on account metadata and a stored representation of the utility’s switching rules, including how many switches are allowed, enrollment windows, city and alternate energy provider assignment, and historical thresholds. The optimizer then simulates monthly or billing-period costs for every eligible plan and alternative energy provider combination and selects the cheapest per-period strategy while enforcing switching limits and other constraints, for example "no more than N switches per year."
Orchestration, validation and learning
The workflow, which is orchestrated end-to-end, downloads bills, extracts usage, ingests tariff JSON, runs eligibility checks, computes costs, and emits switch recommendations. Validation is continuous: projections are reconciled with historical bills and disagreements, feed schema fixes, versioning, and explicit retraining and patching processes. The system also rejects low-confidence LLM outputs and surfaces ambiguous parses for human review, because tax and PCIA application and generation-credit logic remain brittle across utilities.
The engineering tradeoff is clear: utilize deterministic calculators and per-utility testbeds, use LLMs for schema extraction and code generation, and keep human gates for new or low-confidence policies so the system remains auditable and accurate as it scales.
Put together, the pipeline turns chaotic bills and ugly tariff PDFs into a month-by-month cost simulation and a constrained switching plan, enough structure to pick a lowest-cost path without guessing at how the utility actually applies charges.
In addition to the rate optimization, there are several savings levers we investigate for each customer, location and bill:
Categories of Savings Identified:
Automated Payments
For the final step we do more than pick a plan. We put the money flow on autopilot and keep an eye on it. A scheduler triggers idempotent charge attempts timed to the utility due date. Each attempt uses explicit idempotency keys so retries, duplicate webhooks, or restarted jobs cannot produce double charges.
Charge attempts are driven by a deterministic invoice calculation that folds in the chosen rate plan, credits, and any adjustments. The payment flow implements retry and backoff policies, and exposes reconciliation hooks for failed or disputed charges. Payment intents and webhooks are verified and logged end to end, and webhook handlers reconcile incoming events into a canonical “cash in” table keyed by customer, invoice, payment id, and month.
All users can then access payment and health metrics in real time. Dashboards show autopay status, next scheduled charge, last payment. Operational metrics such as charge success rate, retry latency, dispute rate, and time-to-resolution feed alerts so issues are caught before they cascade into late fees. That visibility closes the loop: rate changes become billed and collected events that are continuously monitored and re-scored when reality diverges from forecast.
Utility bills were never built for decisions
Bills arrive late, buried in PDFs, and full of obscure line items: franchise surcharges, public-purpose programs, non-bypassable charges, and power-factor adjustments. Every utility formats things differently, and none of the portals summarize how one site compares to another or what action to take. The default tooling is transactional: clunky portals, siloed logins, buried downloads, and little operational context.
A decision-ready dataset
The dashboard begins with a consistent ingestion and normalization layer. Raw bills, interval usage feeds, and tariff documents are parsed into a uniform JSON schema; those structured rows are then enriched with contextual metadata and baselines so the system can separate normal seasonal variation from real anomalies. Interval series are aligned to meter timezones and billing windows so clock-based logic (for example TOU bands and 15-minute demand peaks) maps correctly to every rate calculation.
What the dashboard surfaces

Bills and invoices. A bills page exposes per-bill metadata and an invoices view ties bills to payment state (invoice id, due date, payment id, status). Both pages support filtering and bulk downloads so operators can extract audit packages quickly.
Permissioned roles. User, operator, and admin roles limit who can view or act; admin functions execute scripts and are gated by least-privilege controls so operations remain auditable.
Autopay and reconciliation views. Dashboards show autopay status, next scheduled charge, and last payment. Payments, expected invoices, and reconciliations are stored in canonical “cash in” and “cash out” models keyed by customer, invoice, payment id, and month so finance can detect mismatches quickly.
For an interactive walkthrough of these screens and flows, browse the interactive demo.
Engineering patterns behind the UI
The dashboard is built on a few repeatable engineering patterns that keep the surface fast, secure, and auditable without tying it to any single vendor.
Warehouse-first, OLAP-backed model. Raw operational data is ingested into a central analytical store where it is cleaned and modeled. Daily snapshots and pre-aggregations feed the interactive UI so the app serves precomputed tiles (month-to-date spend, after-hours index, outliers) instead of running expensive ad-hoc scans. A small, reserved compute layer or materialized views keep those top-level queries sub-second for a responsive user experience.
Tenant isolation and safe file delivery. Multi-tenant isolation is enforced at the data layer using row-level rules or filtered views so each customer only sees their rows. Files never leak raw storage addresses into the browser; downloads go through a backend signer that mints short-lived URLs on demand and redirects the client, keeping object storage opaque and time-limited.
Idempotent exports and batch settlement. Large exports and settlement jobs are implemented as streaming tasks that compose PDFs and write CSV/Parquet manifests. Jobs are idempotent, detect and skip duplicates, and emit a canonical manifest for accounting systems. That pattern lets the same code reliably handle a few dozen invoices or many thousands without manual intervention.
Together these patterns separate concerns: modeling and validation in the warehouse, fast serving through precomputed layers, secure access via a compact API, and robust batch processing for exports, which makes the dashboard practical at scale while preserving auditability and operational safety.
Operational capabilities the dashboard enables
Cross-Location Insights. Energy per square foot and similar normalized KPIs let operators compare the energy intensity of their locations on an apples-to-apples basis once usage and floor-area metadata are attached to meters. Open/close efficiency reports compare interval data to operating hours so overnight HVAC or lighting waste is easy to spot.
Anomaly detection and benchmarks. Interval streams and baseline models let the system surface spikes, leaks, or abnormal loads. Hourly demand curves are benchmarked against peer stores and modeled expectations so issues are flagged immediately.
Practical outcomes for finance and ops
A single, consistent view replaces the scramble across portals and spreadsheets: every bill across every provider is normalized into the same schema, daily snapshots and power finance reports make accruals and audit exports trivial. Role-based access, signed downloads, and a clear export path mean controllers can produce audit-ready packets in seconds rather than weeks.
Closing the loop
By combining parsed bills, interval usage, tariff schemas, and a production data platform, the dashboard becomes a control center rather than a reporting wall. It turns late, opaque invoices into continuous operational signals and supports the workflows that take insight to action. For a hands-on look at how these pieces fit together, check the dashboard demo for an interactive walkthrough.
Technical FAQ
Q: How do you handle portal changes when utilities redesign their sites?
A: The extraction agent uses adaptive selectors and layout analysis. When a portal change causes a failure, the system automatically retries with regenerated selectors, flags the issue for review, and queues a fix proposal. Human review approves changes before deployment to prevent silent data corruption. Typical recovery time is under 30 minutes.
Q: What happens when LLM parsing confidence is low?
A: Every parsed field carries a confidence score and provenance. Low-confidence fields or safety-critical values (totals, meter IDs, usage quantities) trigger fallback to deterministic rule-based extraction. If both methods disagree or confidence remains low, the record routes to human review rather than silently publishing potentially incorrect data.
Q: How do you validate the 99.5% parsing accuracy claim?
A: Parsed totals are reconciled against billed amounts. We run end-to-end validation: parsed line items must sum to within sub-dollar precision of the stated bill total. The cost engine's projections are continuously validated against subsequent actual bills, with discrepancies feeding schema refinement and retraining workflows.
Q: How does the system handle utilities with non-standard rate structures?
A: The tariff schema is designed to be utility-agnostic. Each tariff is translated into a normalized JSON representation encoding all billable components (TOU bands, demand tiers, riders, credits). The cost engine applies these rules deterministically. For truly novel structures, LLMs generate initial code which then undergoes validation against historical bills before production use.
Q: What's the approach to handling hundreds of different utility APIs and portals?
A: Most utilities don't have APIs—access is primarily via authenticated portal scraping. The ingestion pipeline is built for fault tolerance: idempotent runs, automatic retry with exponential backoff, rate limiting, and concurrency controls. Each utility portal has a dedicated extractor that adapts to its specific authentication flow and data export mechanism.
Share article
Ready to see what your current vendor is missing?
Book a free audit. No cost, no commitment, and no disruption to your current setup. We'll show you exactly what's in your bills.
Resources
Learn more about energy savings
Stay up to date with our latest publications.
Why Operators Prefer TrueMeter Over Schneider Electric
Schneider Electric is a utility bill payment service owned by Schneider Electric SE, a French multinational corporation that has offerings in physical generation assets, energy technology, and digitalization for industry. Their bill pay platform processes utility bills for multi-location businesses at $3-17 per bill with no savings optimization. This per-bill model creates a structural misalignment. Schneider Electric is paid the same amount whether or not your bill is accurate or optimized.
CFOs
Engineers
Operators
30 Apr 2026
|
5 min

Why Operators Prefer TrueMeter Over Engie Impact
Most utility bill management providers focus on one outcome: getting invoices paid on time. Engie Impact fits that mold. Their service centers on collecting bills, running tolerance checks, and presenting consolidated invoices for funding, while clients pay on a per-invoice basis with no direct link between fees and the savings produced.
Engineers
Operators
CFOs
30 Apr 2026
|
5 min

Keeping Utilities Honest: The TrueMeter Story
I've lived and worked in many different cities and countries throughout my life. Across all of them, I've yet to find one where utilities worked properly, charged fairly, and didn't spark controversy. The frustrations seemed universal: confusion over electricity bills that don't make sense, costs that surge without explanation, and that nagging feeling you're being overcharged.
CFOs
Engineers
Operators
30 Apr 2026
|
7 min
